

I thought isolating vocals from a song was impossible—until I found Demucs.
If you’ve ever tried extracting vocals or instruments from a track, you know the struggle. Most tools leave behind ghostly echoes or muddy artifacts. But Demucs, an open-source AI-powered audio separator, changes the game. Developed by Meta, it doesn’t just remove vocals—it intelligently reconstructs high-quality stems, making it an essential tool for musicians, producers, and audio engineers.
No more hours spent tweaking EQ settings or wrestling with half-baked filters. Demucs uses deep learning to separate vocals, drums, bass, and other instruments with stunning clarity. Whether you’re remixing, creating karaoke tracks, or analyzing music composition, this tool delivers professional-grade results.
If you’re still using outdated methods to isolate vocals, you’re wasting time.
In this guide, we’ll walk through how to install and use Demucs on your system, ensuring you get the best results from this open-source powerhouse.
🔥 Ready to transform the way you separate audio? Let’s dive in.
What is Demucs? A Powerful AI for Audio Separation
Demucs (Deep Extractor for Music Sources) is an open-source deep learning model designed to separate different elements of an audio track—such as vocals, drums, bass, and other instruments—into isolated stems. Developed by Meta (formerly Facebook AI Research), Demucs leverages recurrent neural networks (RNNs) and convolutional layers to achieve high-quality audio separation that rivals even commercial tools.
Unlike traditional FFT-based (Fast Fourier Transform) separation methods, which often produce robotic-sounding artifacts, Demucs reconstructs waveforms in a more natural and expressive way. This makes it a favorite among musicians, producers, and audio engineers looking for clean and accurate instrument separation.
· · ─ ·𖥸· ─ · ·
Why Use Demucs?
- High-Quality Separations: The deep learning model behind Demucs offers better precision and clarity than traditional audio separation techniques, minimizing artifacts and distortions.
- Open-Source and Community Driven: As an open-source project, Demucs is freely accessible and constantly improved by a community of contributors, ensuring cutting-edge performance.
- Cross-Platform Support: Demucs can be used on various platforms, including Windows, macOS, and Linux, and can be integrated into different workflows via the command line.
· · ─ ·𖥸· ─ · ·
How Demucs Works
Demucs processes audio input through a convolutional neural network designed to separate sound into multiple channels based on frequency patterns and timing. These channels correspond to specific components like vocals, bass, or drums. The tool outputs these components as individual audio files, which can then be modified, mixed, or analyzed independently.
The network is trained on large datasets comprising diverse genres to ensure it performs effectively on both popular and niche music styles. This versatility makes it a popular tool among a wide range of users, from casual enthusiasts to professional producers.
· · ─ ·𖥸· ─ · ·
Key Use Cases of Demucs
- Music Production and Remixing:
Demucs allows producers to isolate vocals, drums, or other instruments from existing tracks, providing the raw elements necessary to remix or build new music from pre-recorded works. DJs can also extract specific components, such as acapella vocals or drum loops, for use in live performances or mashups. - Karaoke Track Creation:
By extracting the vocal component of a song, Demucs can generate instrumental-only tracks that are perfect for karaoke enthusiasts or practice sessions for musicians. - Educational and Analytical Purposes:
Music students and analysts can use Demucs to study the arrangement of individual elements in a piece, better understanding the interplay between instruments, rhythms, and harmonies. - Audio Restoration and Forensics:
Demucs can assist in audio forensics or restoration projects, where isolating certain elements (such as background music) from a recording is needed for analysis or enhancement.
· · ─ ·𖥸· ─ · ·
Prerequisites
Before we start, ensure you have the following installed on your system:
- Python 3.6 or later: You can download it from the official Python website.
- Demucs: This can be installed using pip.
- FFmpeg: A tool required for audio processing. You can download it from the FFmpeg website.
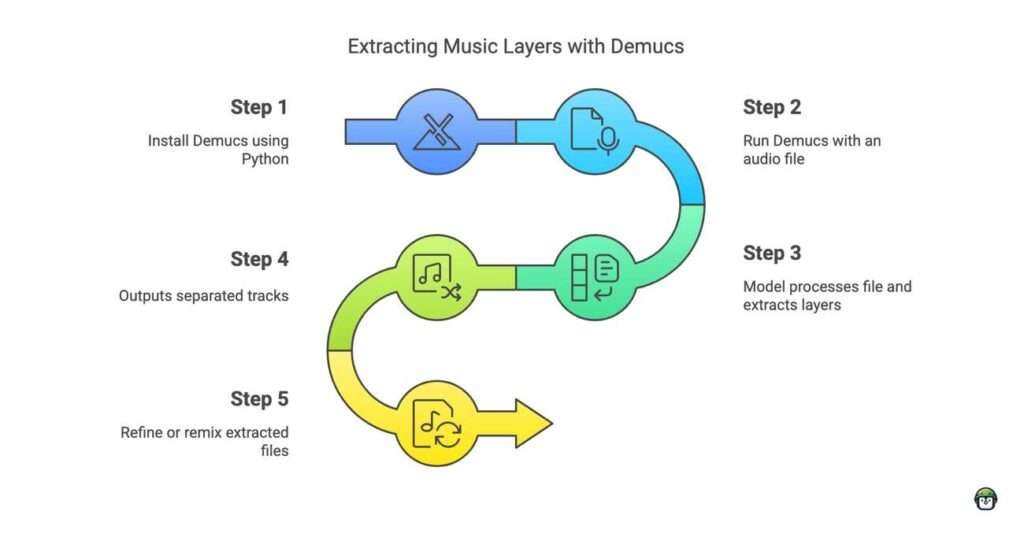
Step 1: Install Demucs
First, let’s install Demucs and its dependencies. Open your terminal or command prompt and run the following command:
pip install demucsUpdate: As of Nov 3, 2024, I have been having problems installind demucs on my machine. I tried installing directly from githhub to no avail. I also tried purging the pip cache, no cigar. Here’s the solution.
python3 -m pip install -U demucsStep 2: Prepare Your Audio File
Ensure your audio file is in a compatible format (e.g., MP3, WAV). For this example, we’ll assume you have an MP3 file named song.mp3.
Step 3: Use Demucs to Separate the Audio
Create a Python script named separate_audio.py and add the following code:
# Ensure FFmpeg is available
os.system("ffmpeg -version")
# Command to run Demucs
command = "demucs --mp3 song.mp3"
# Execute the command
os.system(command)This script uses the os module to execute shell commands. The demucs --mp3 song.mp3 command tells Demucs to process song.mp3 and output the separated components.
Step 4: Run the Script
Execute your script by running the following command in your terminal:
python separate_audio.pyDemucs will process the audio file and create separate files for each component (vocals, drums, bass, and other) in a new directory named separated.
Step 5: Verify the Output
Navigate to the separated directory to find the processed audio files. You should see something like this:
separated/
└── song/
├── vocals.wav
├── drums.wav
├── bass.wav
└── other.wav· · ─ ·𖥸· ─ · ·
Additional Options
Demucs offers various options for customization. For example, you can specify a different model or change the output format. To see all available options, run:
$ demucs --help· · ─ ·𖥸· ─ · ·
Handling NumPy Compatibility Issues
If you encounter an issue where a module compiled with NumPy 1.x cannot run in NumPy 2.0.1, you need to either downgrade NumPy or rebuild the module. Here’s how to do it:
Downgrade NumPy
Uninstall Current NumPy Version:
$ pip uninstall numpyInstall Compatible NumPy Version:
$ pip install 'numpy<2'· · ─ ·𖥸· ─ · ·

· · ─ ·𖥸· ─ · ·
Demucs: Unlock Studio-Quality Audio Separation
Gone are the days of struggling with messy EQ settings or subpar filters. Demucs brings AI-powered precision to audio separation, making it easier than ever to extract clean vocals, drums, bass, and more. Whether you’re remixing, making karaoke tracks, or studying music production, this open-source tool puts professional-grade results at your fingertips.
But don’t just take my word for it—try it yourself. Install Demucs today and experience the difference in audio clarity.
Ready to level up your audio game? Start separating tracks like a pro now.
You might also want to check these:
- eBook Library Themes and Plugins: Customizing Your Digital Collection
- Benefits of Self-Hosting eBooks: Why It’s the Best Choice for Your Library
- DIY Karaoke Videos with FFmpeg and SRT: Format, Sync, and Style
- Automate Chord Transcription Using Sonic Annotator and Vamp Plugins on macOS (Terminal)
- Efficiently Manage Playback Sound in Ubuntu Using mpg321
- How to Use Google Text-to-Speech (gTTS) for Fast and Natural Speech Synthesis in Ubuntu
- How to Pause and Play cvlc from the Terminal
- Convert WAV Files to Text Using Whisper API
- Audiobook Heaven: Setting Up Your Self-Hosted Audio Library
- Self-Hosted Audiobook Library: Tools and Best Practices
- Audio Segmentation: A Simple Guide to Splitting Long Audio Files with FFmpeg
- How to Use cvlc to Play Audio from the Terminal
- How to Use Whisper CLI for Audio Transcription and Translation
Leave a Reply